今天Icebear要實作排序演算法簡介中的另外3個演算法
積排序(HeapSort)
運作方式 :
在堆積的資料結構中,堆積中的最大值總是位於根節點(在優先佇列中使用堆積的話堆積中的最小值位於根節點)。堆積中定義以下幾種操作:
- 最大堆積調整(Max Heapify):將堆積的末端子節點作調整,使得子節點永遠小於父節點
- 建立最大堆積(Build Max Heap):將堆積中的所有數據重新排序
- 堆積排序(HeapSort):移除位在第一個數據的根節點,並做最大堆積調整的遞迴運算
堆積節點的存取 :是通過一維陣列來實現的,在陣列起始位置為0的情形中:
• 父節點i的左子節點在位置(2i+1);
• 父節點i的右子節點在位置(2i+1);
• 子節點i的父節點在位置(2i+1);
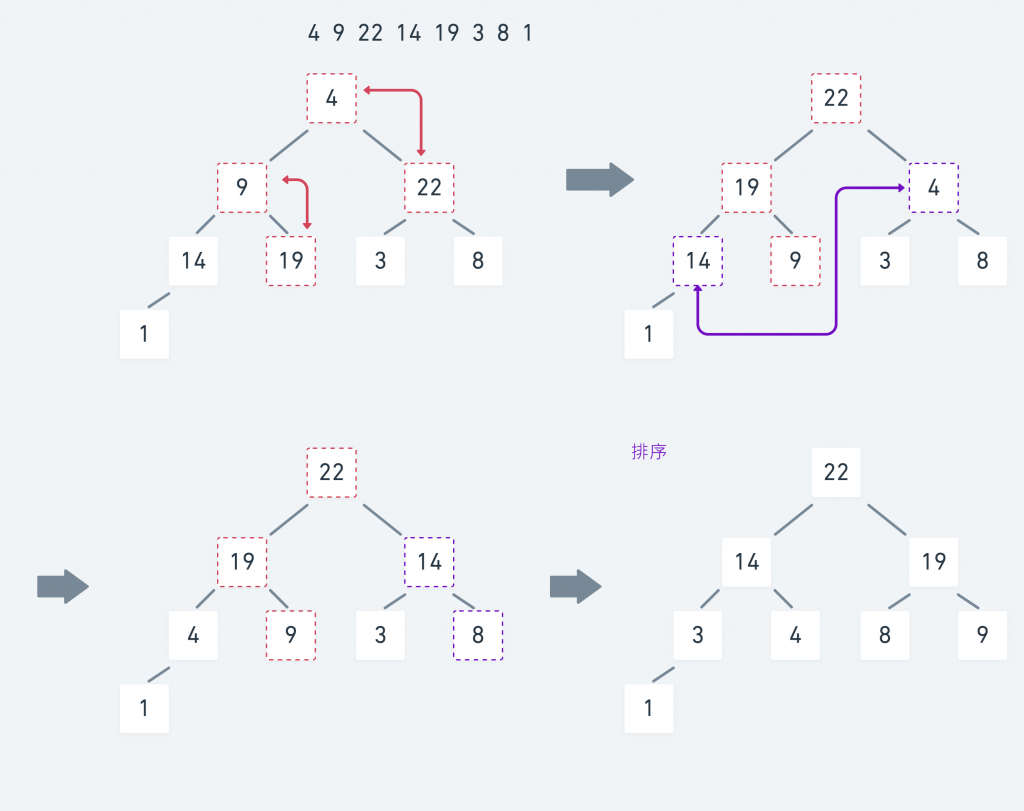
執行過程 :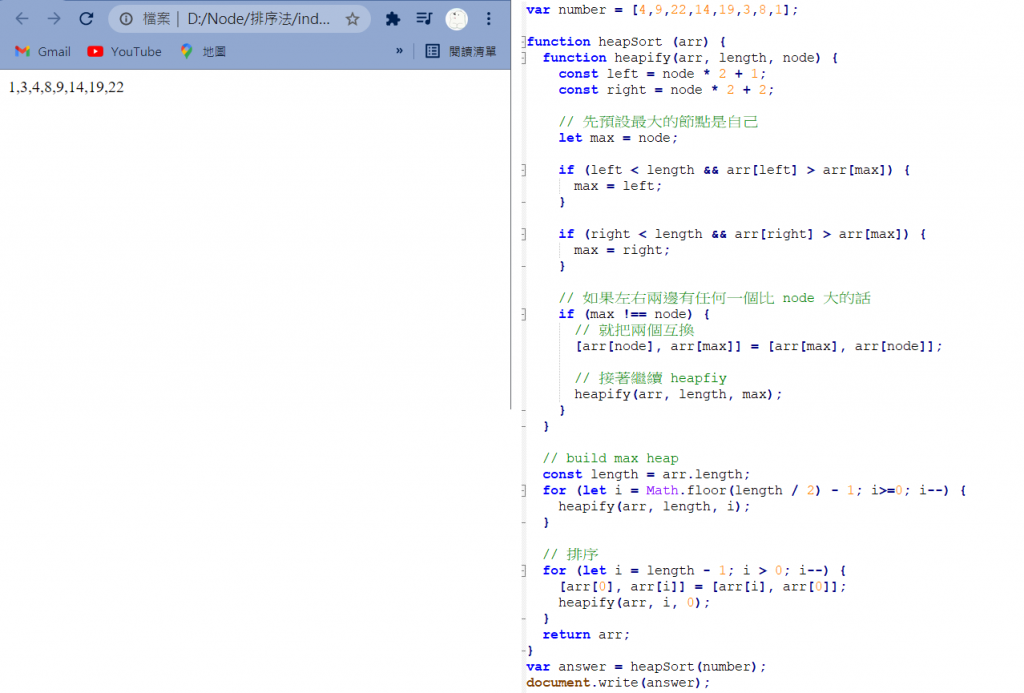
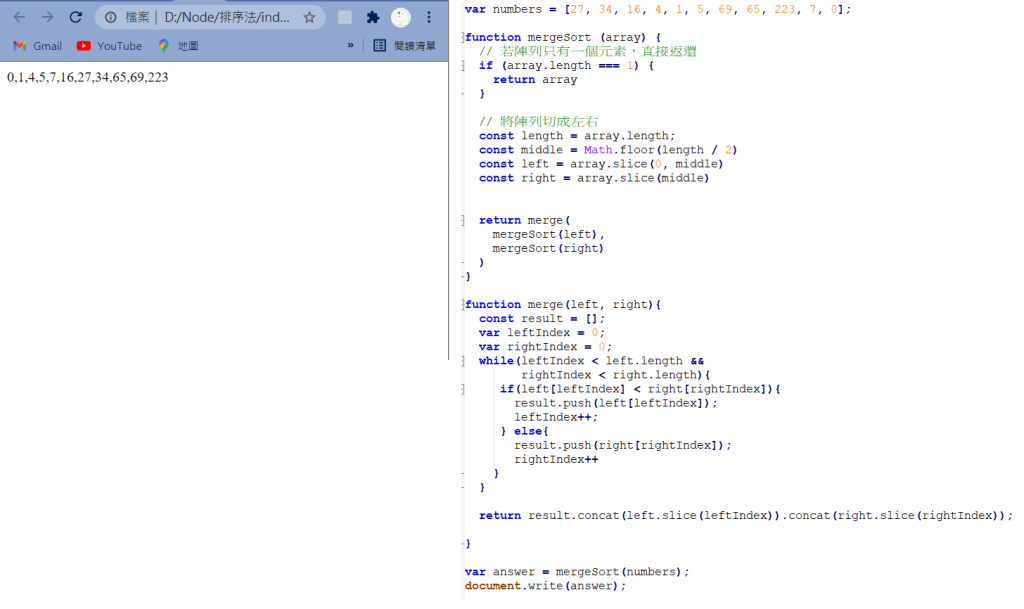
合併排序(MergeSort)
運作方式 :
• 遞迴法(Top-down)
- 申請空間,使其大小為兩個已經排序序列之和,該空間用來存放合併後的序列
- 設定兩個指標,最初位置分別為兩個已經排序序列的起始位置
- 比較兩個指標所指向的元素,選擇相對小的元素放入到合併空間,並移動指標到下一位置
- 重複步驟3直到某一指標到達序列尾
- 將另一序列剩下的所有元素直接複製到合併序列尾
• 迭代法(Bottom-up)
- 原理如下(假設序列共有n個元素)
- 將序列每相鄰兩個數字進行合併操作,形成(n/2)個序列,排序後每個序列包含兩/一個元素
- 若此時序列數不是1個則將上述序列再次合併,形成(n/4)個序列,每個序列包含四/三個元素
- 重複步驟2,直到所有元素排序完畢,即序列數為1
Array.slice() : 意思是截取陣列的某部分,小括號內是要指定擷取片段的begin和 end -> array.slice( begin , end )
執行過程
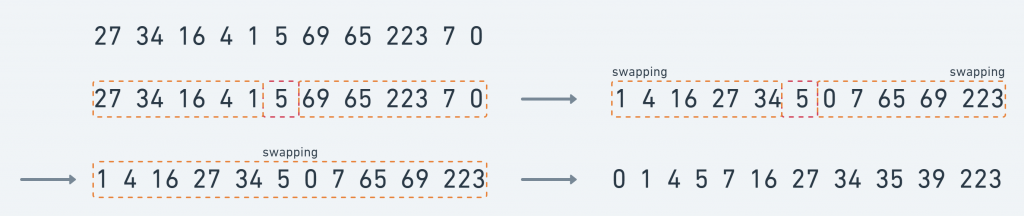
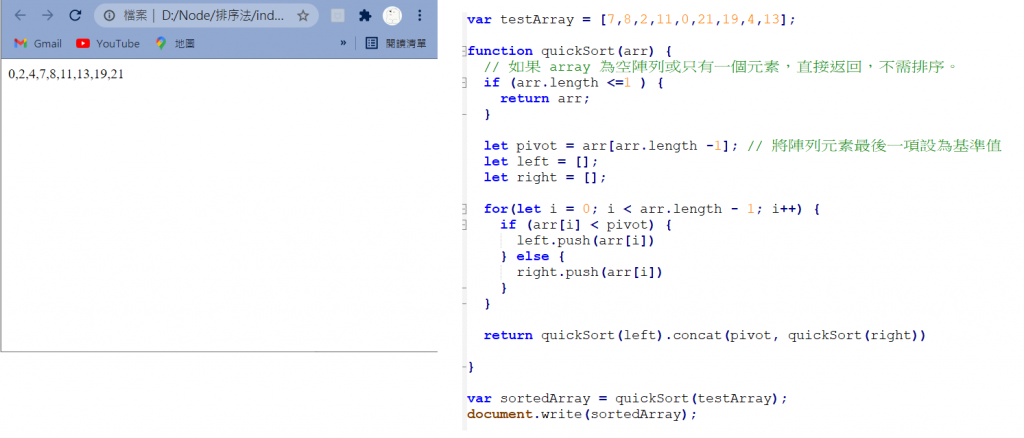
快速排序(QuickSort)
運作方式 :
- 挑選基準值:從數列中挑出一個元素,稱為「基準」(pivot)。
- 分割:重新排序數列,所有比基準值小的元素擺放在基準前面 ;所有比基準值大的元素擺在基準後面(與基準值相等的數可以到任何一邊)。在這個分割結束之後,對基準值的排序就已經完成。
- 遞迴排序子序列:利用遞迴將基準值左右的子序列排序。
通常在挑選基準值時,會挑選中間值或是接近平均值、第一個數或是最後一個數,基準值的選擇恨執行的效率息息相關,所以千萬不要隨便亂選 !!
執行過程